
Page 91 - sjsi
P. 91
Research Article: Alsibai & Heydari 91
that SGD generally performs better on image trained weights frozen except for its final Linear
classification tasks. The optimizer and the layer. This method is recommended in the
learning rate are closely related, as the paper (19) for models trained on ImageNet
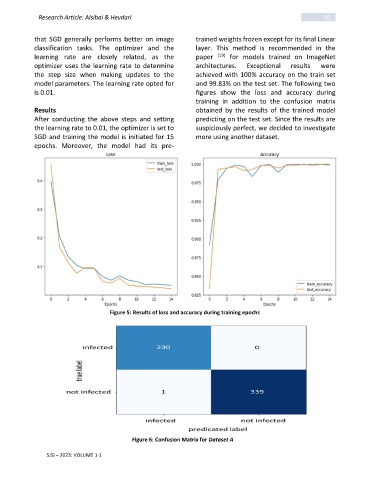
optimizer uses the learning rate to determine architectures. Exceptional results were
the step size when making updates to the achieved with 100% accuracy on the train set
model parameters. The learning rate opted for and 99.83% on the test set. The following two
is 0.01. figures show the loss and accuracy during
training in addition to the confusion matrix
Results obtained by the results of the trained model
After conducting the above steps and setting predicting on the test set. Since the results are
the learning rate to 0.01, the optimizer is set to suspiciously perfect, we decided to investigate
SGD and training the model is initiated for 15 more using another dataset.
epochs. Moreover, the model had its pre-
Figure 5: Results of loss and accuracy during training epochs
Figure 6: Confusion Matrix for Dataset A
SJSI – 2023: VOLUME 1-1